Aby można było wykonać upgrade VM Windows do wersji 11 musimy odpowiednio przygotować VM. Do VM Windows musimy dodać TPM2 oraz przestawić z Bios na UEFI.
Dodanie TPM2
VM > Hardware > Add > TPM State
Zmina BIOS na UEFI
Microsoft w Win10 udostępnił narzędzie do zmiany z mbr na efi.
Dla bezpieczeństwa w Proxmox robimy snapshot dla VM, którą będziemy modyfikować.
W cmd z prawmi admina(niektóre polecenia nie będa działały w powershell prawidłowo) uruchamiamy sprawdzanie możliwości konwersji
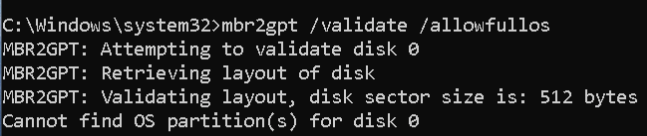
mbr2gpt /validate /allowFullOS
Na tym etapie możemy napotkać błąd:
Cannot find OS partition(s) for disk 0
Częstą przyczyną tego problemu są błądne wpisy w bcd odnośnie partycji recovery.
Przyczynę problemu możemy zidentyfikować w logach c:\windows\setuperr.log oraz c:\windows\setupact.log. Mogą być tam wpisy podobne do „FindOSPartitions: Cannot get volume name for the recovery boot entry”
Polecenie bcedit /enum all pokaże ramdisk=[unknown]

Możemy usunąć ten wpis jeżeli nie potrzebujemy recovery w naszym Windows
Poleceniem bcdedit bez parametrów pobieramy identyfikator „recoverysequence” z sekcji Windows „Boot Loader”
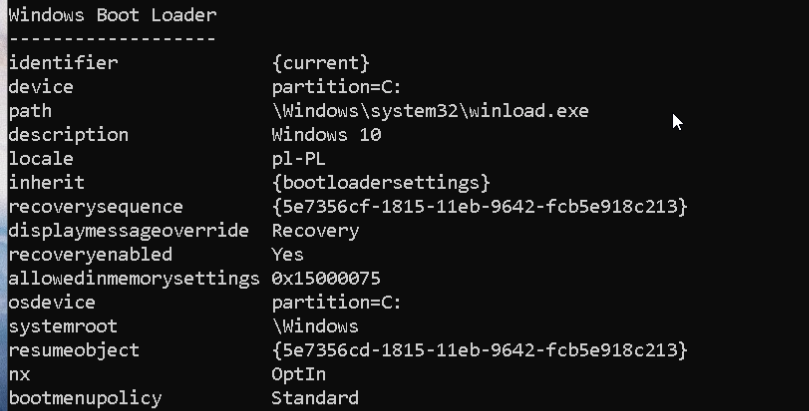
Teraz możemy usunąć wpis, który powoduje problemy
bcedit /delete {recoverysequence}

po tej operacji polecenie bcedit /enum all nie powinno pokazać już wpisu zawierającego ramdisk=[unknown]
możemy ponownie uruchomić walidację przed zmianą mbr2gpt /validate /allowFullOS
Jeżeli polecenie z mbr2gpt z parametrem validate nie pokazuje błędu to możemu zacząć konwersję, jako disk:x podajemy dysk zidentyfikowany w poleceniu validate np disk:0
mbr2gpt /convert /disk:x /allowFullOS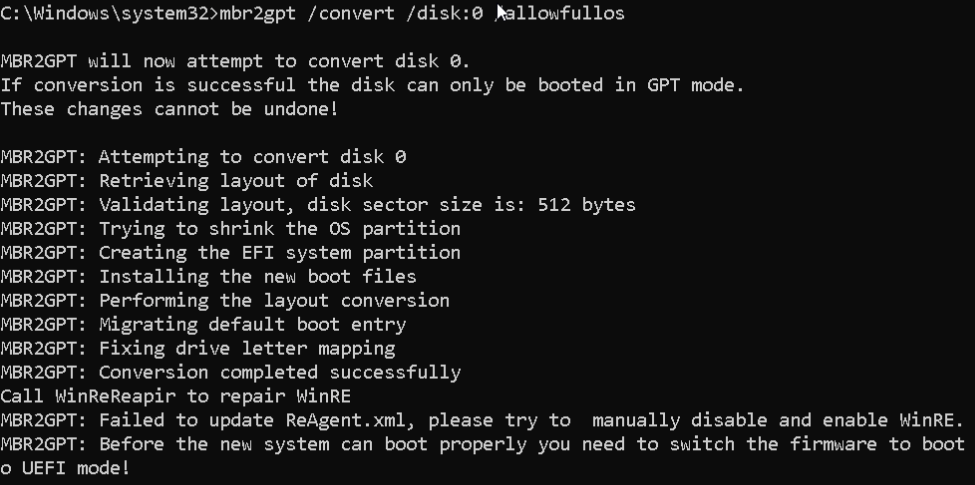
Możesz natknąć się na komunikat błedu. Failed to update ReAgent.xml, ja go zignorowałem bez dalszych konsekwencji.
Wyłączamy maszynę i w Proxmox Dodajemy EFI Disk z zaznaczona opcją Pre-Enroll Keys, partycję EFI dodaję zawsze na tym samym zasobie co główny dysk VM’ki.
VM > Hardware > Add > EFI Disk oraz opcję BIOS zmieniamy na OVMF (UEFI).
Uruchamiamy VM.
Gdy Windows się uruchomił możemy usunąć snapshota
Na VM możemy sprawdzić czy wszystkie wymagania do aktualizacji są spełnione programem od Microsoft PC Health Check App