Sprawdza stan Twojego bezpiecznego kanału oraz nazwę kontrolera domeny, którego dotyczy zapytanie.
nltest /sc_query:domena.comSprawdzanie zastosowanych obiektów zasad grup
gpresult /rSprawdza stan Twojego bezpiecznego kanału oraz nazwę kontrolera domeny, którego dotyczy zapytanie.
nltest /sc_query:domena.comSprawdzanie zastosowanych obiektów zasad grup
gpresult /rW cmd Fortigate możemy sprawdzić przynależność do grup użytkownika w LDAP.
# diagnose test authserver ldap (LDAP server_name) (username) (password)Gdy domena AD przestaje ufać komputerowi, prawdopodobnie dzieje się tak dlatego, że hasło komputera lokalnego nie pasuje do hasła przechowywanego w usłudze Active Directory.
Aby usługa AD mogła ufać komputerowi, oba hasła muszą być zsynchronizowane. Jeśli nie są zsynchronizowane, pojawi się niesławny komunikat o błędzie „Błąd relacji zaufania między tą stacją roboczą a domeną podstawową ” .
Niestety, nigdy nie było ani jednego rozwiązania, które działałoby w 100% przypadków.
Gdy nowy komputer jest dodawany do usługi Active Directory, tworzone jest konto komputera z hasłem. To hasło jest domyślnie ważne przez 30 dni. Po 30 dniach zmienia się automatycznie. Jeśli zmieni się, a hasło klienta nie, pojawi się komunikat o błędzie „relacja zaufania między tą stacją roboczą a domeną podstawową nie powiodła się”.
Aby sprawdzić, że to ten problem występuje logujemy się na kliencie jako admin lokalny i w Power Shellu uruchamiamy
> Test-ComputerSecureChannel
FalseFalse oznacza, że zaufanie nie istnieje.
Możemy użyć też cmd w starszych systemach
nltest /sc_verify:<your domain FQDN>Jako admin na kliencie wykonujemy:
> Reset-ComputerMachinePasswordJako admin na kliencie wykonujemy:
netdom resetpwd /s:DC /ud:abertram /pd:*Jako admin na kliencie wykonujemy:
> Test-ComputerSecureChannel -Repair -Credential (Get-Credential)Przygotowane na podstawie: https://adamtheautomator.com/the-trust-relationship-between-this-workstation-and-the-primary-domain-failed/
Skrypcik pobiera kompiluje i instaluje moduły jądra do VMWare Player/Worstation
VMWARE_VER=workstation-16.2.4
FOLDER=/tmp/patch-vmware
rm -fdr $FOLDER
mkdir -p $FOLDER
cd $FOLDER
git clone https://github.com/mkubecek/vmware-host-modules.git
cd $FOLDER/vmware-host-modules
git checkout $VMWARE_VER
git fetch
make
sudo make install
sudo rm /usr/lib/vmware/lib/libz.so.1/libz.so.1
sudo ln -s /lib/x86_64-linux-gnu/libz.so.1 /usr/lib/vmware/lib/libz.so.1/libz.so.1 Kernelstub to narzędzie do automatycznego zarządzania partycją systemową EFI (ESP) systemu operacyjnego.
Aby zobaczyć, które wersje jądra są zainstalowane i określić dokładne numery wersji, uruchom:
# dpkg --list | grep linux-image*
ii linux-image-5.18.10-76051810-generic
ii linux-image-5.19.0-76051900-genericTeraz zmieniamy domyślną wersję jądra używaną podczas uruchamiania systemu, możesz to zrobić wybierając wersje jądra z zainstalowanych w systemie, podając jako parametry odpowiednie vmlinuz i initrd znajdujące się w katalogu /boot:
# kernelstub -v -k /boot/vmlinuz-5.18.10-76051810-generic -i /boot/initrd.img-5.18.10-76051810-generic
Tworzymy plik
$ su zimbra
$ touch /opt/zimbra/conf/custom_header_checksDodajemy go do konfiguracji Zimbry
$ zmprov mcf zimbraMtaHeaderChecks 'pcre:/opt/zimbra/conf/postfix_header_checks pcre:/opt/zimbra/conf/custom_header_checks'
$ zmprov mcf zimbraMtaBlockedExtensionWarnRecipient FALSESprawdzamy czy nowy plik z regułami testowania nagłówka został pobrany przez Zimbra:
$ postconf | grep header_checks
header_checks = pcre:/opt/zimbra/conf/postfix_header_checks, pcre:/opt/zimbra/conf/custom_header_checks
...Dodajemy nagłówki które chcemy ignorować do pliku custom_header_checks
$ nano /opt/zimbra/conf/custom_header_checks
/^Received: from localhost/ IGNORE
/^Received:.*with ESMTPSA/ IGNORE
/^User-Agent:/ IGNORE
Restartujemy MTA
$ zmmtactl restartNa podstawie: https://wiki.zimbra.com/wiki/How_to_disable_various_headers
Uzyskiwanie listy kategorii reguł zainstalowanych w naszym systemie:
$ cut -d\" -f2 /opt/so/rules/nids/all.rules | grep -v "^$" | grep -v "^#" | awk '{print $1, $2}'|sort |uniq -c |sort -nrWyłączenie konkretnej kategorii używając wyrażeń regularnych
$ sudo so-rule disabled add 're:GPL TELNET'Wyłączenie reguły według wybranego SID reguły
$ sudo so-rule disabled add 222222Sprawdzenie listy wyłączonych reguł
$ sudo so-rule disabled listAby mieć pewność, możemy sprawdzić czy reguła została zakomentowana w /opt/so/rules/nids/all.rules
$ grep 222222 /opt/so/rules/nids/all.rulesWsystkie te wyjątki zapisywane są do pliku /opt/so/saltstack/local/pillar/minions/<managername>_<role>.sls do sekcji idstools
Możemy wyciszyć i ustawiać progi wywołania alertów dodając do pliku /opt/so/saltstack/local/pillar/global.sls lub /opt/so/saltstack/local/pillar/minions/<MINION_ID>.sls sekcję thresholding
Progowanie:
thresholding:
sids:
8675309:
- threshold:
gen_id: 1
type: threshold
track: <by_src | by_dst>
count: 10
seconds: 10Wyciszenie:
thresholding:
sids:
8675309:
- suppress:
gen_id: 1
track: <by_src | by_dst | by_either>
ip: <ip | subnet>Po zmianie w plikach .sls musimy ponownie uruchomić Suriacata.
$ sudo sudo so-suricata-restart <--force>Na podstawie https://docs.securityonion.net/en/2.3/managing-alerts.html
Na podstawie https://ubuntu.com/server/docs/service-sssd-ad.
Opis uwierzytelnienia użytkowników w komputerze z Linux w domenie Active Directory.
Przed rozpoczęciem pracy aby ułatwić sobie późniejszą konfigurację i użytkowanie, upewniamy się, że w naszym systemie nie ma użytkownika o nazwie takiej jak użytkownik domenowy, którego będziemy używać .
Instalujemy potrzebne oprogramowanie.
$ sudo apt install sssd-ad sssd-tools realmd adcliSprawdzamy /etc/hostname oraz /etc/hosts.
$ cat /etc/hostname
moj-komputer
$ cat cat /etc/hostname
127.0.0.1 localhost
::1 localhost
127.0.1.1 moj-komputer.domena.example.local moj-komputerSprawdzamy czy domena jest wykrywana przez DNS.
$ sudo realm -v discover domena.example.localJeżeli mamy problemy z dostępem do domeny to musimy sprawdzić konfigurację DNS. W Ubuntu i Pop-os używany jest lokalny serwer DNS, który domyślnie nie rozwiązuje domen *.local. Konfiguracja DNS.
Dołączamy do domeny
$ sudo realm join -v domena.example.localNarzędzie realm zajęło się już stworzeniem konfiguracji sssd, dodaniem modułów pam i nss oraz uruchomieniem niezbędnych usług.
Teraz musimy sprawdzić konfigurację /etc/sssd/sssd.conf:
[sssd]
domains = domena.example.local
config_file_version = 2
services = nss, pam
[domain/domena.example.local]
default_shell = /bin/bash
krb5_store_password_if_offline = True
cache_credentials = True
krb5_realm = DOMENA.EXAMPLE.LOCAL
realmd_tags = manages-system joined-with-adcli
id_provider = ad
fallback_homedir = /home/%u@%d
ad_domain = domena.example.local
use_fully_qualified_names = True
ldap_id_mapping = True
access_provider = adPlik musi mieć uprawnienia 0600 i własność root:root
Włączamy i uruchamiamy ponownie serwis sssd
$ sudo systemctl enable sssd
$ sudo systemctl restart sssdAutomatyczne tworzenie katalogu domowego dla użytkowników domenowych
$ sudo pam-auth-update --enable mkhomedirDodanie obsługi Kerberos
$ sudo apt install krb5-userKonfiguracja pliku /etc/krb5-user.conf
[libdefaults]
default_realm = DOMENA.EXAMPLE.LOCAL
rdns = no
dns_lookup_kdc = true
dns_lookup_realm = true
[realms]
DOMENA.EXAMPLE.LOCAL = {
kdc = kontroler_domeny.domena.example.local
admin_server = kontroler_domeny.domena.example.local
}Testowanie biletu Kerberos
$ kinit user@domena.example.local
$ klistAby zalogować się pierwszy raz do pulpitu za pomocą użytkownika Active Directory wybieramy na ekranie logowania „Nie wymienione” i wpisujemy użytkownika domenowego w formacie user@domena.example.local.
Domyślnie Pop-os i Ubuntu używa do rozwiązywania nazw lokalnego DNS. Czasem może to powodować problemy np. nie są rozwiązywane domeny .local.
Możemy ustawić system aby bezpośrednio korzystał z wpisanego w konfiguracji sieci DNS’a zmieniając dowiązanie symboliczne pliku /etc/resolv.conf.
sudo rm -f /etc/resolv.conf
sudo ln -s /run/systemd/resolve/resolv.conf /etc/resolv.confW Security Onion 2 Elasticsearch otrzymuje nieprzeanalizowane logi z Logstash lub Filebeat . Elasticsearch analizuje i przechowuje te logi. Parsery są przechowywane w /opt/so/conf/elasticsearch/ingest/. Własne parsery można umieścić w /opt/so/saltstack/local/salt/elasticsearch/files/ingest/. Jeżeli twój parser będzie posiadał nazwę identyczną ze standardową to zostanie nadpisany.
Do parsowania logów używamy różnych procesorów. Jednym z nich jest Grok. Pisząc lub edytując własny parser z użyciem Grok możemy skorzystać z debugera w Kibana > Dev Tools > Grok Debugger
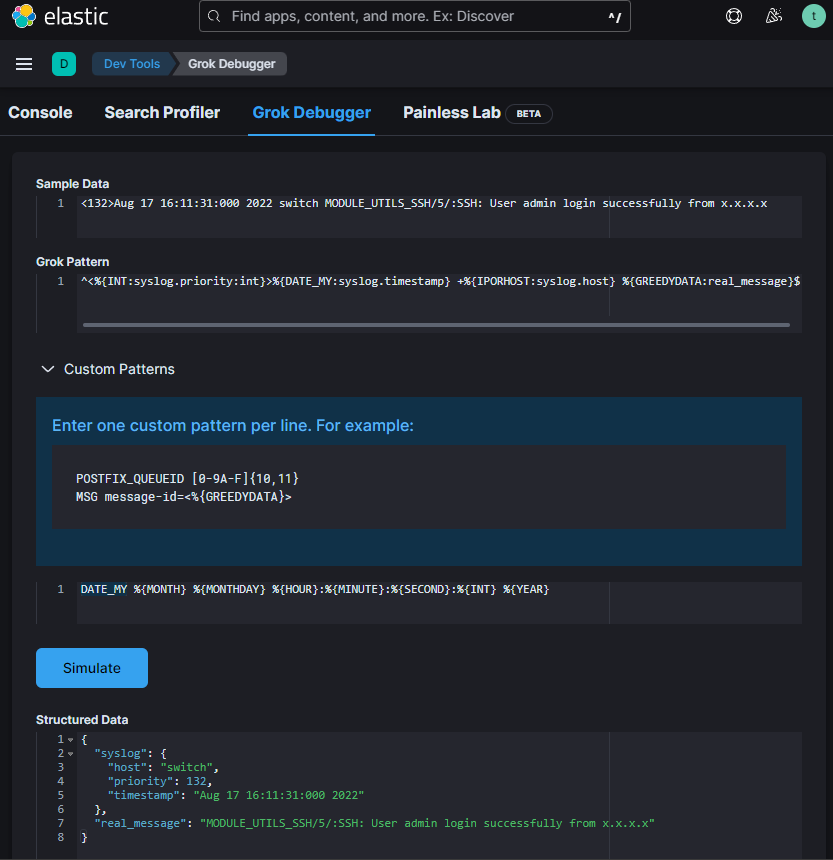
„Sample Data” – to fragment logów który parsujemy
„Grok Pattern” – wzorzec
„Custom Patterns” – wzorce niestandardowe używane w Grok pattern.
W Grok pattern możemy użyć też standardowych wzorców.
Na podstawie wzorca zmodyfikowałem plik /opt/so/conf/elasticsearch/ingest/syslog zapisując go w /opt/so/saltstack/local/salt/elasticsearch/files/ingest/syslog, aby prawidłowo parsował mój log „<132>Aug 17 16:11:31:000 2022 switch MODULE_UTILS_SSH/5/:SSH: User admin login successfully from x.x.x.x”
{
"description" : "syslog pipeline",
"processors" : [
{
"dissect": {
"field": "message",
"pattern" : "%{message}",
"on_failure": [ { "drop" : { } } ]
},
"remove": {
"field": [ "type", "agent" ],
"ignore_failure": true
}
}, {
"grok": {
"field": "message",
"patterns": [
"^<%{INT:syslog.priority:int}>%{TIMESTAMP_ISO8601:syslog.timestamp} +%{IPORHOST:syslog.host} +%{PROG:syslog.program}(?:\\[%{POSINT:syslog.pid:int}\\])?: %{GREEDYDATA:real_message}$",
"^<%{INT:syslog.priority}>%{DATA:syslog.timestamp} %{WORD:source.application}(\\[%{DATA:pid}\\])?: %{GREEDYDATA:real_message}$",
"^%{SYSLOGTIMESTAMP:syslog.timestamp} %{SYSLOGHOST:syslog.host} %{SYSLOGPROG:syslog.program}: CEF:0\\|%{DATA:vendor}\\|%{DATA:product}\\|%{GREEDYDATA:message2}$",
"^<%{INT:syslog.priority:int}>%{DATE_MY:syslog.timestamp} +%{IPORHOST:syslog.host} %{GREEDYDATA:real_message}$"
],
"pattern_definitions" : {
"DATE_MY" : "%{MONTH} %{MONTHDAY} %{HOUR}:%{MINUTE}:%{SECOND}:%{INT} %{YEAR}"
},
"ignore_failure": true
}
},
{
"convert" : {
"if": "ctx?.syslog?.priority != null",
"field" : "syslog.priority",
"type": "integer"
}
},
{
...Patterns są przetwarzane od góry do doły aż zostanie znaleziony pasujący wzorzec.
Aby zmiany zostały uwzględnione przeładowałem Elasticsearch:
$ sudo so-elasticsearch-restart