W Security Onion 2 Elasticsearch otrzymuje nieprzeanalizowane logi z Logstash lub Filebeat . Elasticsearch analizuje i przechowuje te logi. Parsery są przechowywane w /opt/so/conf/elasticsearch/ingest/. Własne parsery można umieścić w /opt/so/saltstack/local/salt/elasticsearch/files/ingest/. Jeżeli twój parser będzie posiadał nazwę identyczną ze standardową to zostanie nadpisany.
Do parsowania logów używamy różnych procesorów. Jednym z nich jest Grok. Pisząc lub edytując własny parser z użyciem Grok możemy skorzystać z debugera w Kibana > Dev Tools > Grok Debugger
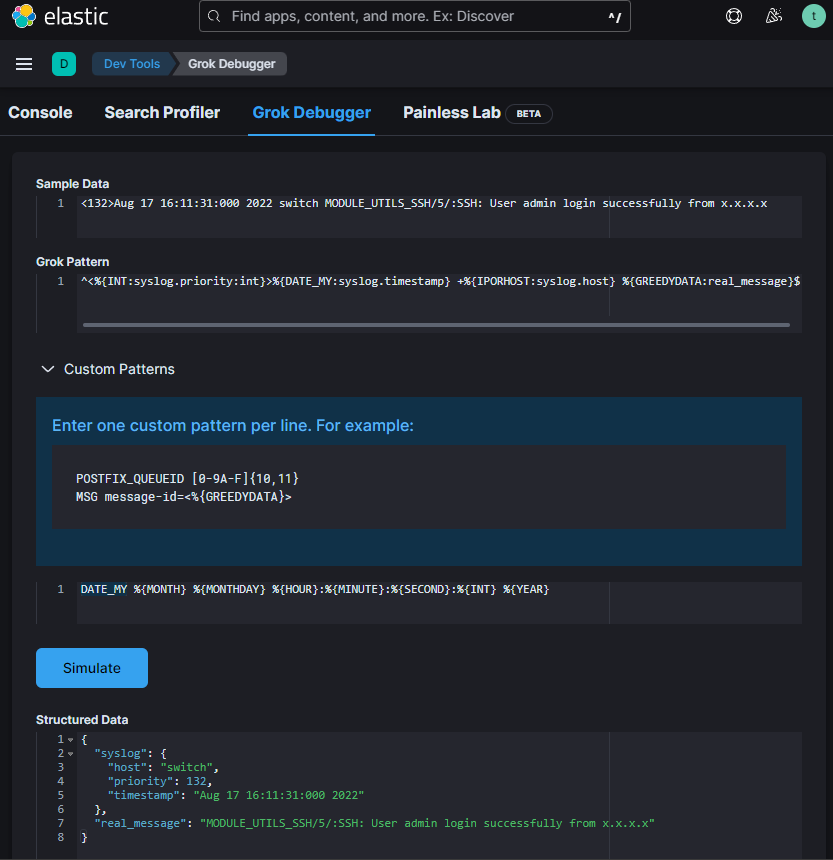
„Sample Data” – to fragment logów który parsujemy
„Grok Pattern” – wzorzec
„Custom Patterns” – wzorce niestandardowe używane w Grok pattern.
W Grok pattern możemy użyć też standardowych wzorców.
Na podstawie wzorca zmodyfikowałem plik /opt/so/conf/elasticsearch/ingest/syslog zapisując go w /opt/so/saltstack/local/salt/elasticsearch/files/ingest/syslog, aby prawidłowo parsował mój log „<132>Aug 17 16:11:31:000 2022 switch MODULE_UTILS_SSH/5/:SSH: User admin login successfully from x.x.x.x”
{
"description" : "syslog pipeline",
"processors" : [
{
"dissect": {
"field": "message",
"pattern" : "%{message}",
"on_failure": [ { "drop" : { } } ]
},
"remove": {
"field": [ "type", "agent" ],
"ignore_failure": true
}
}, {
"grok": {
"field": "message",
"patterns": [
"^<%{INT:syslog.priority:int}>%{TIMESTAMP_ISO8601:syslog.timestamp} +%{IPORHOST:syslog.host} +%{PROG:syslog.program}(?:\\[%{POSINT:syslog.pid:int}\\])?: %{GREEDYDATA:real_message}$",
"^<%{INT:syslog.priority}>%{DATA:syslog.timestamp} %{WORD:source.application}(\\[%{DATA:pid}\\])?: %{GREEDYDATA:real_message}$",
"^%{SYSLOGTIMESTAMP:syslog.timestamp} %{SYSLOGHOST:syslog.host} %{SYSLOGPROG:syslog.program}: CEF:0\\|%{DATA:vendor}\\|%{DATA:product}\\|%{GREEDYDATA:message2}$",
"^<%{INT:syslog.priority:int}>%{DATE_MY:syslog.timestamp} +%{IPORHOST:syslog.host} %{GREEDYDATA:real_message}$"
],
"pattern_definitions" : {
"DATE_MY" : "%{MONTH} %{MONTHDAY} %{HOUR}:%{MINUTE}:%{SECOND}:%{INT} %{YEAR}"
},
"ignore_failure": true
}
},
{
"convert" : {
"if": "ctx?.syslog?.priority != null",
"field" : "syslog.priority",
"type": "integer"
}
},
{
...Patterns są przetwarzane od góry do doły aż zostanie znaleziony pasujący wzorzec.
Aby zmiany zostały uwzględnione przeładowałem Elasticsearch:
$ sudo so-elasticsearch-restart