W cmd Fortigate możemy sprawdzić przynależność do grup użytkownika w LDAP.
# diagnose test authserver ldap (LDAP server_name) (username) (password)W cmd Fortigate możemy sprawdzić przynależność do grup użytkownika w LDAP.
# diagnose test authserver ldap (LDAP server_name) (username) (password)Tworzymy plik
$ su zimbra
$ touch /opt/zimbra/conf/custom_header_checksDodajemy go do konfiguracji Zimbry
$ zmprov mcf zimbraMtaHeaderChecks 'pcre:/opt/zimbra/conf/postfix_header_checks pcre:/opt/zimbra/conf/custom_header_checks'
$ zmprov mcf zimbraMtaBlockedExtensionWarnRecipient FALSESprawdzamy czy nowy plik z regułami testowania nagłówka został pobrany przez Zimbra:
$ postconf | grep header_checks
header_checks = pcre:/opt/zimbra/conf/postfix_header_checks, pcre:/opt/zimbra/conf/custom_header_checks
...Dodajemy nagłówki które chcemy ignorować do pliku custom_header_checks
$ nano /opt/zimbra/conf/custom_header_checks
/^Received: from localhost/ IGNORE
/^Received:.*with ESMTPSA/ IGNORE
/^User-Agent:/ IGNORE
Restartujemy MTA
$ zmmtactl restartNa podstawie: https://wiki.zimbra.com/wiki/How_to_disable_various_headers
Uzyskiwanie listy kategorii reguł zainstalowanych w naszym systemie:
$ cut -d\" -f2 /opt/so/rules/nids/all.rules | grep -v "^$" | grep -v "^#" | awk '{print $1, $2}'|sort |uniq -c |sort -nrWyłączenie konkretnej kategorii używając wyrażeń regularnych
$ sudo so-rule disabled add 're:GPL TELNET'Wyłączenie reguły według wybranego SID reguły
$ sudo so-rule disabled add 222222Sprawdzenie listy wyłączonych reguł
$ sudo so-rule disabled listAby mieć pewność, możemy sprawdzić czy reguła została zakomentowana w /opt/so/rules/nids/all.rules
$ grep 222222 /opt/so/rules/nids/all.rulesWsystkie te wyjątki zapisywane są do pliku /opt/so/saltstack/local/pillar/minions/<managername>_<role>.sls do sekcji idstools
Możemy wyciszyć i ustawiać progi wywołania alertów dodając do pliku /opt/so/saltstack/local/pillar/global.sls lub /opt/so/saltstack/local/pillar/minions/<MINION_ID>.sls sekcję thresholding
Progowanie:
thresholding:
sids:
8675309:
- threshold:
gen_id: 1
type: threshold
track: <by_src | by_dst>
count: 10
seconds: 10Wyciszenie:
thresholding:
sids:
8675309:
- suppress:
gen_id: 1
track: <by_src | by_dst | by_either>
ip: <ip | subnet>Po zmianie w plikach .sls musimy ponownie uruchomić Suriacata.
$ sudo sudo so-suricata-restart <--force>Na podstawie https://docs.securityonion.net/en/2.3/managing-alerts.html
W Security Onion 2 Elasticsearch otrzymuje nieprzeanalizowane logi z Logstash lub Filebeat . Elasticsearch analizuje i przechowuje te logi. Parsery są przechowywane w /opt/so/conf/elasticsearch/ingest/. Własne parsery można umieścić w /opt/so/saltstack/local/salt/elasticsearch/files/ingest/. Jeżeli twój parser będzie posiadał nazwę identyczną ze standardową to zostanie nadpisany.
Do parsowania logów używamy różnych procesorów. Jednym z nich jest Grok. Pisząc lub edytując własny parser z użyciem Grok możemy skorzystać z debugera w Kibana > Dev Tools > Grok Debugger
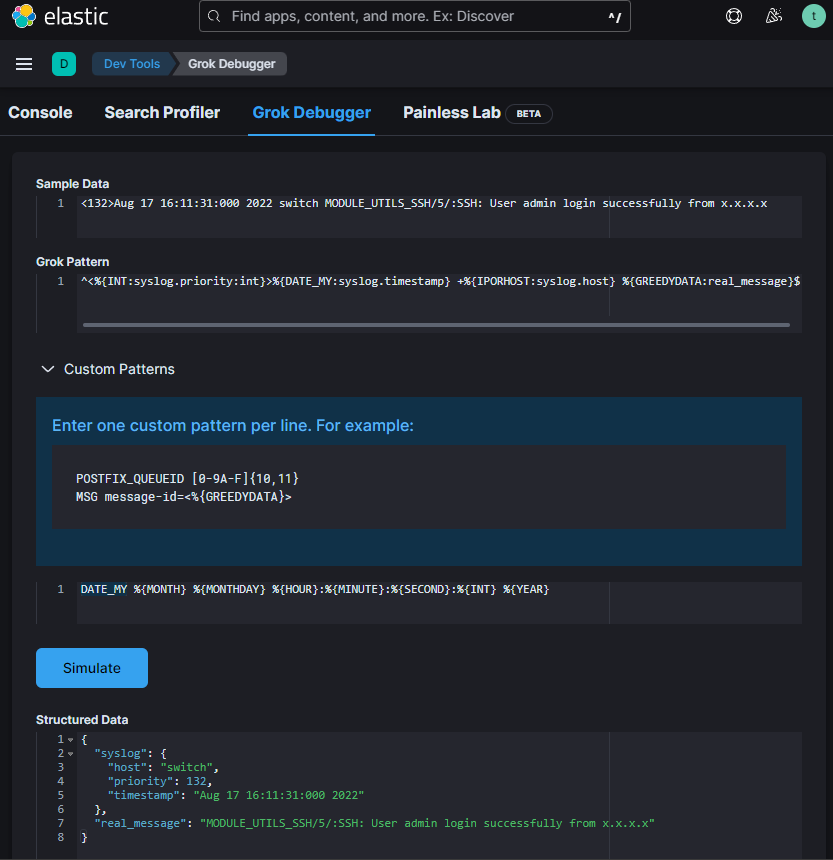
„Sample Data” – to fragment logów który parsujemy
„Grok Pattern” – wzorzec
„Custom Patterns” – wzorce niestandardowe używane w Grok pattern.
W Grok pattern możemy użyć też standardowych wzorców.
Na podstawie wzorca zmodyfikowałem plik /opt/so/conf/elasticsearch/ingest/syslog zapisując go w /opt/so/saltstack/local/salt/elasticsearch/files/ingest/syslog, aby prawidłowo parsował mój log „<132>Aug 17 16:11:31:000 2022 switch MODULE_UTILS_SSH/5/:SSH: User admin login successfully from x.x.x.x”
{
"description" : "syslog pipeline",
"processors" : [
{
"dissect": {
"field": "message",
"pattern" : "%{message}",
"on_failure": [ { "drop" : { } } ]
},
"remove": {
"field": [ "type", "agent" ],
"ignore_failure": true
}
}, {
"grok": {
"field": "message",
"patterns": [
"^<%{INT:syslog.priority:int}>%{TIMESTAMP_ISO8601:syslog.timestamp} +%{IPORHOST:syslog.host} +%{PROG:syslog.program}(?:\\[%{POSINT:syslog.pid:int}\\])?: %{GREEDYDATA:real_message}$",
"^<%{INT:syslog.priority}>%{DATA:syslog.timestamp} %{WORD:source.application}(\\[%{DATA:pid}\\])?: %{GREEDYDATA:real_message}$",
"^%{SYSLOGTIMESTAMP:syslog.timestamp} %{SYSLOGHOST:syslog.host} %{SYSLOGPROG:syslog.program}: CEF:0\\|%{DATA:vendor}\\|%{DATA:product}\\|%{GREEDYDATA:message2}$",
"^<%{INT:syslog.priority:int}>%{DATE_MY:syslog.timestamp} +%{IPORHOST:syslog.host} %{GREEDYDATA:real_message}$"
],
"pattern_definitions" : {
"DATE_MY" : "%{MONTH} %{MONTHDAY} %{HOUR}:%{MINUTE}:%{SECOND}:%{INT} %{YEAR}"
},
"ignore_failure": true
}
},
{
"convert" : {
"if": "ctx?.syslog?.priority != null",
"field" : "syslog.priority",
"type": "integer"
}
},
{
...Patterns są przetwarzane od góry do doły aż zostanie znaleziony pasujący wzorzec.
Aby zmiany zostały uwzględnione przeładowałem Elasticsearch:
$ sudo so-elasticsearch-restartW Wazuh domyślnie można przeglądać tylko logi z rozpoznanych alertów. Możemy jednak tak ustawić aby Wazuh indeksował i umożliwił przeglądanie wszystkich wysyłanych do niego logów.
w pliku konfiguracji /var/ossec/etc/ossec.conf ustawiamy
# nano /var/ossec/etc/ossec.conf
<logall_json>yes</logall_json>
# systemctl restart wazuh-manager Zmieniamy konfigurację Filebeat aby czytał i wysyłał alerty i archiwa
# nano /etc/filebeat/filebeat.yml
filebeat.modules:
- module: wazuh
alerts:
enabled: true
archives:
enabled: true
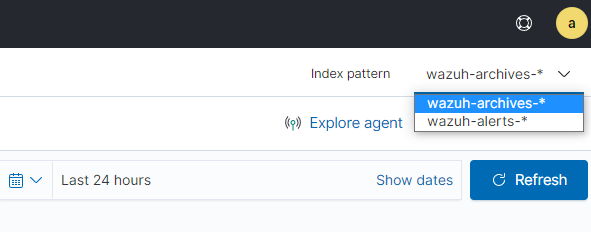
# systemctl restart filebeatLogujemy się do dashboard Wazuh i dodajemy wzór indeksu.
Menu -> Management -> Stack Management -> Index Patterns -> Create index pattern
Teraz w „Security events” po prawej stronie u góry możemy wybierać wzór indexu „Index pattern”
W niektórych konfiguracjach sieciowych, gdzie klient bacula-fd jest w podsieci z której nie ma dostępu do repozytorium bacula-sd możemy odwrócić połączenie i to bacula-sd nawiązuje połączenie z clientem bacula-fd. Dzieki takiej konfiguracji ewentualny zainfekowany klient nie będzie miał dostępu do repozytorium bacula-sd.
W konfiguracji bacula-dir.conf w sekcji Client dodajemy SDCallsClient = yes
Client {
Name = SerwerPlikow
Address = X.X.X.X
FDPort = 9102
AutoPrune = no
. . .
SDCallsClient = yes
}Wyłączenie mechanizmu akceleracji na jednej polityce np. w celach testowych aby sniffer widział wszystkie przepływające pakiety.
$ config firewall policy
edit 1
set np-acceleration disable
set auto-asic-offload disable
endOperacja czyszczenia file systemu, odzyskuje fizyczną pamięć zajmowaną przez usunięte obiekty w systemie plików Data Domain. Gdy oprogramowanie aplikacji wygaśnie, obrazy kopii zapasowych lub archiwalnych i gdy obrazy nie są obecne w migawce, obrazy nie są dostępne lub nie można ich odzyskać z aplikacji lub migawki, dane nadal zajmują fizyczną pamięć masową. Data Domain okresowo sam czyści file system, ale możemy wykonać ręczne czyszczenie z poziomu CLI.
Połacz się z Data Domain przez ssh
$ filesys show space #sprawdza wolne miejsce
$ filesys clean start #uruchomienie czyszczenia
$ filesys clean watch #podgląd procesuNiektóre strony internetowe nadal pracują w starszej wersji ssl/tls. Jeżeli nasza polityka firewall pracuje w trybie proxy, to takie połączenie może nie zostać zrealizowane prawidłowo.
Możemy obniżyć minimalną wersję ssl/tls na profilu ssl-ssh, który wykorzystujemy w naszej polityce firewall.
$ config firewall ssl-ssh-profile
$ edit <nazwa_profilu_ssl-ssh>
$ config https
$ set min-allowed-ssl-version tls-1.0
$ end Przeglądanie i usuwanie sesji z poziomu cli
$ diagnose sys session filter ?
vd Index of virtual domain. -1 matches all.
vd-name Name of virtual domain. -1 or "any" matches all.
sintf Source interface.
dintf Destination interface.
src Source IP address.
nsrc NAT'd source ip address
dst Destination IP address.
proto Protocol number.
sport Source port.
nport NAT'd source port
dport Destination port.
policy Policy ID.
expire expire
duration duration
proto-state Protocol state.
session-state1 Session state1.
session-state2 Session state2.
ext-src Add a source address to the extended match list.
ext-dst Add a destination address to the extended match list.
ext-src-negate Add a source address to the negated extended match list.
ext-dst-negate Add a destination address to the negated extended match list.
clear Clear session filter.
negate Inverse filter.Ustawiamy filtry, i możemy podglądnąć i skasować sesje. Jeżeli żadne filtry nie będą ustawione, zostaną skasowane wszystkie sesje (wszystkie).
# ustawiamy filtr sesji np:
$ diagnose sys session filter src 192.168.1.1 192.168.1.255
# podgląd ustawionych filtrów
$ diagnose sys session filter
session filter:
...
source ip: 192.168.1.1-192.168.1.255
...
# podgląd sesji
$ diagnose sys session list
...
# usuwanie wyfiltrowanych sesji
$ diagnose sys session clear
# usuwanie ustawionych filtrów
$ diagnose sys session filter clear